以前CI関連の勉強会でその存在を知ってから密かに思いを寄せていたTDDBC。
今回はそのTDDBCがYokohama Devtesting と合同でイベントを開催されるということだったので、
こちらのイベントに参加してきました。
TDDBCとは?
TDDを手を動かしながら体験することを目的として、全国各地にてハンズオンイベントを開催しているコミュニティ。
アジャイルとかCIのイベントに参加してるけど、結局何を契機に始めたらいいのかわかんないや みたいな方のためのイベントも。
言語はイベントによって異なる模様(今回はJava)。
Yokohama Devtesting とは?
横浜でソフトウェア開発のテストについて考えるコミュニティ。
月一回のペースにてテスト駆動開発本の読書会も開催されている模様。
イベントの流れ
・TDDに関するプレゼン
・ペアプロデモ
・実際にペアプロ
・コードレビュー
(続きを読む…)
ご無沙汰です。
本当は「数千万件のデータが入ったテーブルでインデックスを構築したらパフォーマンスが劇的に改善された話」というタイトルで書こうと思ったのだけど、書いているうちに内部構造が気になり出したので上記のタイトルに変更。
まずはパフォーマンスが改善された話から
SELECT A FROM hoge WHERE B = ~~~ ORDER BY C DESC;
hogeは数千万件のデータが入ったテーブルで、その中から結果約4万件程のデータのうち A の部分をSELECT。条件としては、カラムBの値が~~~に合致するときで、更には Cという別のカラムで並び替えるというクエリになっている。
結果的に
ALTER TABLE hoge ADD INDEX foo ( B, C, A );
というインデックスを張ることによって、それまで2分以上かかっていたselect文が 0.1秒~0.2秒まで短縮されたという某赤いモビルスーツも驚きのパフォーマンス改善を見せた。
正直インデックスの劇的な威力に感動して、その喜びをブログにつづろうと思い立った所、以下の疑問が生まれたというのが始まり。
すなわち、
何で↓じゃだめなの?
ALTER TABLE hoge ADD INDEX foo ( A, B, C );
という話(どこかのブログで「インデックスは順序左から書かないと意味無いよ」と書いていたので)。
仮説
なんとなーく最近コンパイラをいじっていて記憶に新しい構文木的なにおいがするなあと感じた。
そこで、MySQLの構文解析機構を調べてみたところ、
案の定字句解析と構文解析をそれぞれFlexとBisonで行っているようなので、勉強がてらMySQLの構文解析ロジックを見てみることにした。
調査
丁度GoogleがMySQLのコードを出していたので、MySQLの構文定義部であるsql_yacc.yyの中身を拝見。
http://code.google.com/p/google-mysql/source/browse/sql/sql_yacc.yy?r=d15790ab618324fb1729aa212b244cad5cb9778f
まずは式全体の構文を探す。1600行目でみっけ。
/* Verb clauses, except begin */
statement:
alter
| analyze
| backup
| binlog_base64_event
| call
| change
| check
| checksum
| commit
| create
| deallocate
| delete
| describe
| do
:
:
:
中には「select」もしっかり定義されていたので、続いてselectを探す。
6638行目から始まっているのがそれっぽい。
select:
select_init
{
LEX *lex= Lex;
lex->sql_command= SQLCOM_SELECT;
}
;
/* Need select_init2 for subselects. */
select_init:
SELECT_SYM select_init2
| '(' select_paren ')' union_opt
;
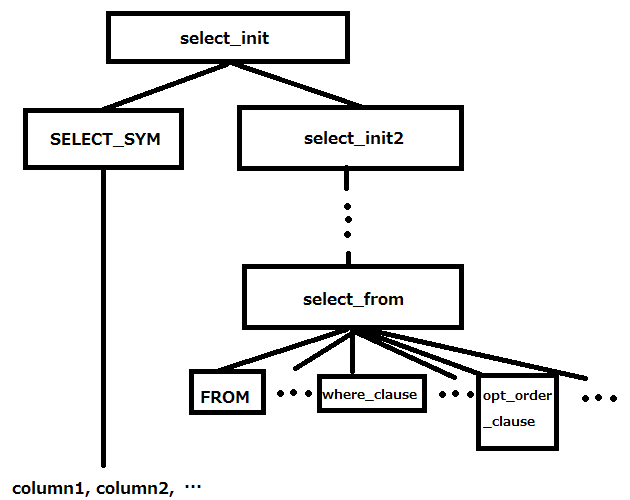
どんどん掘り下げていった結果、だいたいこんな感じになりました。
考察
選択するカラムと where句、order by句、 having 句、group by 句などの条件が明確に分断されていました。
つまり、select_from の部分は、よくあるコンパイラの factor = ( expression ) 的な感じで先に解析されていて、解析が終了した後でSELECT_SYM とがっちゃんこするのではないかと予想(定かではありません)。
こう考えると
ALTER TABLE hoge ADD INDEX foo ( B, C, A );
になるのはそこまで不思議な話ではないかなと感じた。
実際はどうだったのか(2014.03.26追記)
記事の公開後、友人から「covering index 的な話では」とご指摘をいただきました。
Covering Indexに関しては 以下の記事がとても参考になった。
MySQLでインデックスを使って高速化するならCovering Indexが使えそう
もう少しDBまわりの勉強もしないとなあと思いつつ、また新しいことを勉強させていただいた上にMySQLの内部構造にもちょこっと触れられたので 結果としては良かったかなと思った。
構文解析をしていてちょっと詰まったのでメモ。

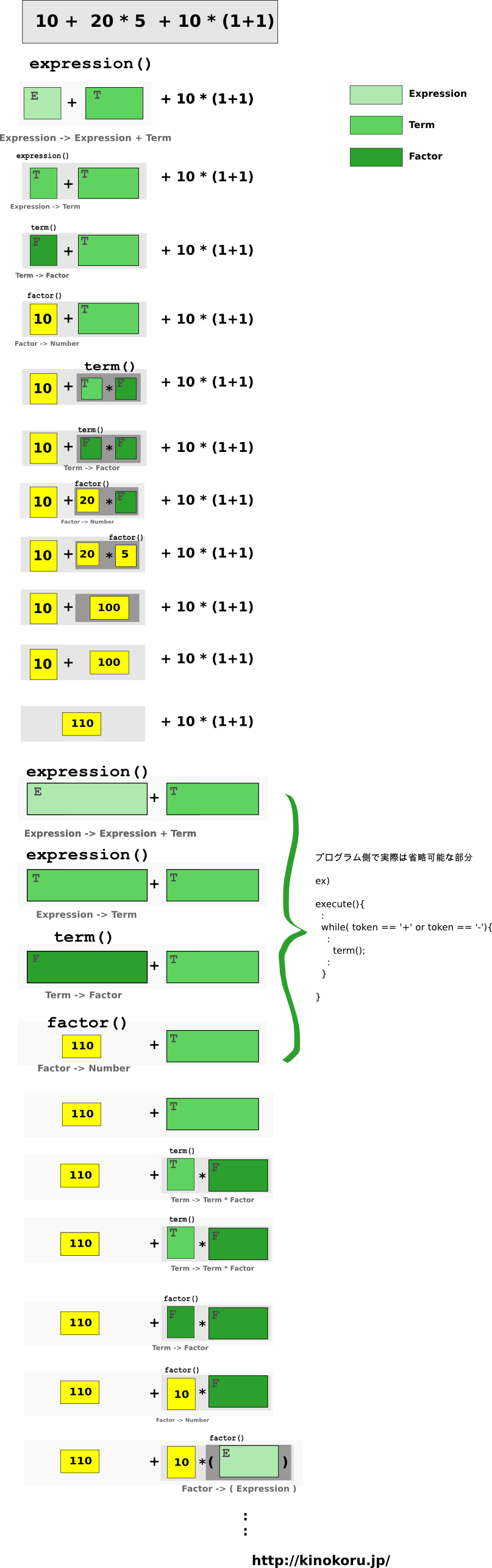
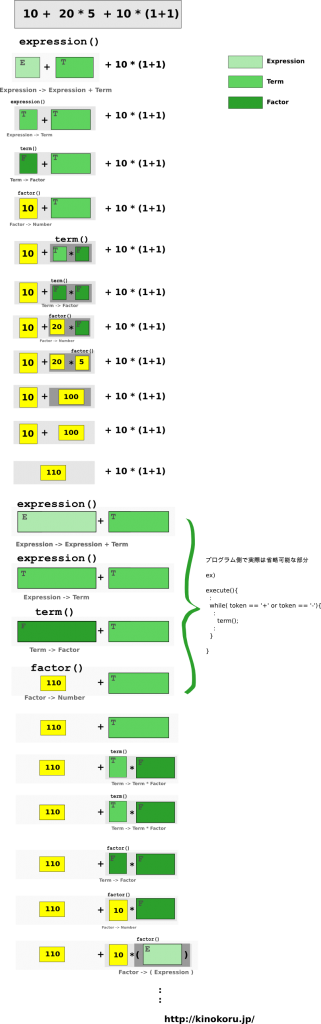
上記の構文規則に基づくとすると、
10 + 20 * 5 + 10 * (1 + 1)
の再帰ルーチンは以下のようになる。
(なお、 expression(), term(), factor() はそれぞれ上記の構文規則を実装した関数 )
(続きを読む…)
ご無沙汰しております。
週末でC言語のポインタ本読了してました。
Web系にいるものの、最近こういう低級言語に触れ合っているとなんとも言えない楽しさを感じるので 会社が終わるとそっちの方ばっかりいじってます。
ところで、ここ数日は色々と細かいタスクが増えてきたので 自分用に簡単なGTDのツールをつくろうとLINQまわりをいじっていました。
今回はXMLの保存・読み込みということで記事投稿。
準備
using System.Xml.Linq; // XDocument オブジェクトを使用する。
using System.IO; // ファイルの保存・読み出し時に必要。
とりあえずアセンブリ参照の追加。
XMLをつくってみる。
XDocument F = new XDocument();
F.Add(new XElement("RootNode")); // ノードの追加
F.Save(FileName);
これで FileName に指定したパス・ファイル名でxmlデータが保存される。
今回はこんな感じ。
<?xml version="1.0" encoding="utf-8"?>
<todolist />
※ XMLにルート要素の追加をせずに保存すると読み出しの際にランタイムエラー吐くので注意。
ちょっといじってみた感じ、よくあるXML操作関連のAPIのような操作性で直感的に操作できて良い感じ。
(続きを読む…)
お久しぶりです。
ブログを更新していないしばらくの間、WPFをいじくり倒してました。おかげさまで、超簡単なデスクトップアプリケーションならなんとかつくれるようになりました。
というわけで週末は勉強がてらWPFでクッキークリッカーっぽいものをつくって遊んでました。
そこで感じたのが、
複数ウィンドウでデリゲートとかイベントとか書いてるうちにクラス間の関係が密結合になってしまうということ。
こういう場合、一つのクラスの規模が大きくなってきて ある属性をクラス化して分離したくなった時とかになかなか面倒くさいので、
一つメディエータみたいな感じのクラスが欲しい。
でもエントリポイントがWPFの一クラスだとあまり綺麗な構造になりそうもないので、
いっそのことエントリポイントをWPFのクラスじゃなくて通常のC#クラスにしてしまって、WPFを分離してはどうか。
さらに各描画用インスタンスを保持するクラスを用意して、複数ウィンドウ間でのイベント処理を楽にしてはどうかという発想に至った。
(API化すれば良い気もするが)
*なお、この記事はC#/WPF超初心者が執筆しているので、参考にする場合は十分に注意してください。また、「いやそもそもこうした方が楽じゃね」っていうところに関してはどんどんご指摘いただければ幸いです。
(続きを読む…)