ご無沙汰です。
本当は「数千万件のデータが入ったテーブルでインデックスを構築したらパフォーマンスが劇的に改善された話」というタイトルで書こうと思ったのだけど、書いているうちに内部構造が気になり出したので上記のタイトルに変更。
まずはパフォーマンスが改善された話から
SELECT A FROM hoge WHERE B = ~~~ ORDER BY C DESC;
hogeは数千万件のデータが入ったテーブルで、その中から結果約4万件程のデータのうち A の部分をSELECT。条件としては、カラムBの値が~~~に合致するときで、更には Cという別のカラムで並び替えるというクエリになっている。
結果的に
ALTER TABLE hoge ADD INDEX foo ( B, C, A );
というインデックスを張ることによって、それまで2分以上かかっていたselect文が 0.1秒~0.2秒まで短縮されたという某赤いモビルスーツも驚きのパフォーマンス改善を見せた。
正直インデックスの劇的な威力に感動して、その喜びをブログにつづろうと思い立った所、以下の疑問が生まれたというのが始まり。
すなわち、
何で↓じゃだめなの?
ALTER TABLE hoge ADD INDEX foo ( A, B, C );
という話(どこかのブログで「インデックスは順序左から書かないと意味無いよ」と書いていたので)。
仮説
なんとなーく最近コンパイラをいじっていて記憶に新しい構文木的なにおいがするなあと感じた。
そこで、MySQLの構文解析機構を調べてみたところ、
案の定字句解析と構文解析をそれぞれFlexとBisonで行っているようなので、勉強がてらMySQLの構文解析ロジックを見てみることにした。
調査
丁度GoogleがMySQLのコードを出していたので、MySQLの構文定義部であるsql_yacc.yyの中身を拝見。
まずは式全体の構文を探す。1600行目でみっけ。
/* Verb clauses, except begin */ statement: alter | analyze | backup | binlog_base64_event | call | change | check | checksum | commit | create | deallocate | delete | describe | do : : :
中には「select」もしっかり定義されていたので、続いてselectを探す。
6638行目から始まっているのがそれっぽい。
select:
select_init
{
LEX *lex= Lex;
lex->sql_command= SQLCOM_SELECT;
}
;
/* Need select_init2 for subselects. */
select_init:
SELECT_SYM select_init2
| '(' select_paren ')' union_opt
;
どんどん掘り下げていった結果、だいたいこんな感じになりました。
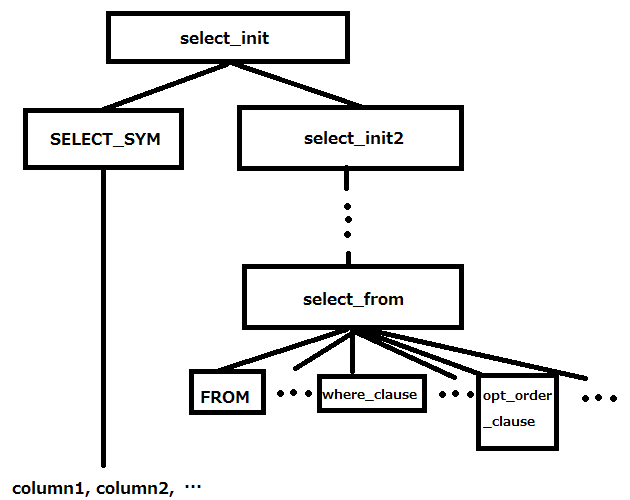
考察
選択するカラムと where句、order by句、 having 句、group by 句などの条件が明確に分断されていました。
つまり、select_from の部分は、よくあるコンパイラの factor = ( expression ) 的な感じで先に解析されていて、解析が終了した後でSELECT_SYM とがっちゃんこするのではないかと予想(定かではありません)。
こう考えると
ALTER TABLE hoge ADD INDEX foo ( B, C, A );
になるのはそこまで不思議な話ではないかなと感じた。
実際はどうだったのか(2014.03.26追記)
記事の公開後、友人から「covering index 的な話では」とご指摘をいただきました。
Covering Indexに関しては 以下の記事がとても参考になった。
MySQLでインデックスを使って高速化するならCovering Indexが使えそう
もう少しDBまわりの勉強もしないとなあと思いつつ、また新しいことを勉強させていただいた上にMySQLの内部構造にもちょこっと触れられたので 結果としては良かったかなと思った。
Written by Nisei Kimura ( 木村 仁星 )
